摘要
在前文《有效祖先数与有效始祖数的计算原理及其在visPedigree中的验证》 中,我们讨论了经典有效始祖数(\(f_e\) )与有效祖先数(\(f_a\) )的计算逻辑。它们本质上都建立在贡献度平方和之上,因此更敏感于头部始祖或祖先的集中贡献,却较难体现低频血统和边缘家系的存在感。此外,经典 \(f_e\) 与 \(f_a\) 更像是某一时点的“截面指标”,难以直接回答多样性正在以多快的速度流失。
visPedigree 1.6.0 引入了基于香农信息熵的 \(f_e^{(H)}\) (feH)\(f_a^{(H)}\) (faH)pedhalflife()
与上一篇更偏重“静态结构拆解”不同,本文更关注两个问题:
当经典 \(f_e\) 、\(f_a\) 看起来尚可时,群体中是否仍然保留着被低估的长尾遗传贡献?
在当前育种模式下,多样性下降的主要压力,究竟更接近于始祖利用不均 、代际瓶颈 ,还是随机漂变 ?
一、核心概念:基于信息熵的有效指标
1.1 经典指标的痛点:平方和带来的集中偏好
经典有效数基于期望贡献度(\(p_i\) 或 \(q_j\) )的平方和计算,可视作 Hill number 中 \(q=2\) 的情形:
\[ f_e = \frac{1}{\sum_{i=1}^{f} p_i^2}, \qquad f_a = \frac{1}{\sum_{j=1}^{a} q_j^2} \]
在求和前先平方,会显著放大高贡献项的权重。例如,20% 的贡献在平方后仍然很突出,而 0.5% 级别的贡献平方后几乎可以忽略。因此,经典有效数更擅长刻画“头部祖先”的集中程度,却不够敏感于低贡献、低频但真实存在的遗传来源。
1.2 \(f_e^{(H)}\) 与 \(f_a^{(H)}\) 计算公式
为了把低频贡献也纳入衡量,visPedigree 引入了信息论中的 香农熵(Shannon entropy,对应 Hill number 的 \(q=1\) ) :
\[ f_e^{(H)} = \exp\!\Bigl(-\sum_{i=1}^{f} p_i \ln p_i\Bigr) \] \[ f_a^{(H)} = \exp\!\Bigl(-\sum_{j=1}^{a} q_j \ln q_j\Bigr) \]
香农熵中的 \(p_i \ln p_i\) 对低频贡献的压缩远弱于平方项,因此能更平衡地反映“长尾”部分的存在。直观地说,经典 \(f_e\) 、\(f_a\) 更强调“头部占了多少”,而 \(f_e^{(H)}\) 、\(f_a^{(H)}\) 还会额外回答“尾部还剩多少”。
所有这四个指标在数学上具有严格的不等式关系: \[ N_f \ge f_e^{(H)} \ge f_e, \qquad K \ge f_a^{(H)} \ge f_a \] (其中 \(N_f\) 为总始祖数,\(K\) 为计算所考虑的总祖先数)
1.3 育种用途:如何读懂“长尾信号”
在育种决策中,除了看绝对值,更值得关注的是 \(\rho = f_e^{(H)} / f_e\) (或 \(f_a^{(H)} / f_a\) )这样的比值:
当比值接近 1 :说明头部祖先几乎定义了全部多样性,长尾贡献较弱;如果多样性继续收缩,单靠群体内部微调的操作空间通常有限。当比值明显大于 1 :说明除核心家系外,群体中仍保留着不少低频贡献。此时如果能在配种中有意识地续留这些边缘家系,往往还有机会延缓多样性进一步收缩。
在应用上,这两个比值最有价值的地方并不在于“谁更大”,而在于它们帮助区分了两种完全不同的管理情形:一种是群体确实已经失去大部分潜在遗传来源,另一种则是潜在来源仍在,但这些来源没有被持续、均衡地传递到下一代。前者更接近“资源不足”问题,后者更接近“管理分配”问题。
1.4 静态指标与动态指标的互补性
从监测逻辑上看,pediv() 与 pedhalflife() 回答的是两个不同层面的问题:
pediv() 回答的是当前参考群体的结构状态 ,即多样性还剩多少、分布是否集中、哪些始祖或祖先贡献过高。pedhalflife() 回答的是历史轨迹的动态趋势 ,即多样性正在以多快的速度流失,以及流失主要来自始祖利用不均、代际瓶颈还是随机漂变。
如果只有 pediv(),我们可以看到“当前还剩多少”,却难以判断这种状态是在改善还是恶化;如果只有 pedhalflife(),我们可以看到“正在如何变化”,却不容易识别当前哪一批家系、哪一类祖先正在构成瓶颈。因此,在年度监控中,静态诊断与动态诊断应被视为互补而非替代的两组证据。
二、遗传多样性半衰期(Diversity Half-Life)
2.1 半衰期的概念
仅知道当前还剩多少多样性并不够,育种管理更关心的是:如果继续沿用现有的配种与留种模式,群体多样性会以多快的速度下降?
pedhalflife() 通过对 \(f_g\) 随时间变化的自然对数进行线性回归,估计总流失率 \(\lambda_{total}\) 。于是,多样性半衰期可以写为: \[ T_{1/2} = \frac{\ln 2}{\lambda_{total}} \]
解读要点 :
这里的半衰期应理解为基于历史趋势的管理指标 。它适合比较不同时间窗、不同留种策略下的流失快慢,但不应被理解为“到了某一年一定减半”的确定性预言。
2.2 多样性流失的成分溯源(三分离法)
仅知道流失多快还不够,还要知道流失主要来自哪里。利用下面的恒等式: \[ \ln fg = \underbrace{\ln fe}_{\text{lnfe}} + \underbrace{\ln\!\left(\frac{fa}{fe}\right)}_{\text{lnfafe}} + \underbrace{\ln\!\left(\frac{fg}{fa}\right)}_{\text{lnfgfa}} \]
由于普通最小二乘法(OLS)对加法分解保持线性,我们可以分别对这三项关于世代(或年份)做回归,从而把总流失速率严格拆解为三个来源:\(\lambda_{total} = \lambda_e + \lambda_b + \lambda_d\) :
始祖效应 \(\lambda_e\) (Foundation) :始祖利用不均随时间加剧所造成的流失。瓶颈效应 \(\lambda_b\) (Bottleneck) :中间世代核心父母本被重复使用,导致遗传来源进一步收缩。漂变效应 \(\lambda_d\) (Drift) :有限群体在代际传递中,由随机抽样带来的等位基因损失。
2.3 pedhalflife() 的常用参数怎么理解?
visPedigree::pedhalflife() 在 1.6.0 中的常用参数如下:
其核心参数可按用途理解:
ped:已经整理好的系谱对象,通常是 tidyped() 的结果。timevar:时间轴变量,默认是 "Gen"。如果数据中有真实年份或批次时间,优先用 Year、BirthYear 这类真实变量,更利于和生产节奏对接。at:只分析某几个指定时间点。例如只想看最近 4 个世代是否加速流失,可以只传入末端年份集合。nsamples:计算共祖或相关指标时的抽样规模。样本越大越稳定,但耗时更长。ncores:并行核数。大数据集可适当提高。seed:随机抽样的种子,用于保证结果可重复。
实践建议 :
若目标是年度管理报告,用 timevar = "Year"。
若目标是理论对比或世代遗传改良分析,用 timevar = "Gen"。
若群体规模非常大,建议显式设置 nsamples 和 seed,保证不同批次分析可以横向比较。
三、实战演练:多世代系谱分析
下面使用真实群体档案 G09_prunedPed.csv(2015 至 2025 年连续繁育记录)演示,这些指标如何从“数学定义”转化为“管理判断”。
3.1 载入数据并格式化处理
library (visPedigree)library (data.table)# 读入真实育种数据集 <- fread ("G09_prunedPed.csv" , na.strings = c ("" , "NA" , "0" ))# 为了适配 tidyped 的默认要求,重命名主要列 setnames (ped_raw, old = c ("AnimalID" , "SireID" , "DamID" , "SexID" ), new = c ("Ind" , "Sire" , "Dam" , "Sex" ))<- tidyped (ped = ped_raw)# 固定随机种子,保证抽样相关结果可复现 <- 20260320 Ldata.table (= c ("总个体数" , "最大世代" , "年份数" ),= c (nrow (tp_g09), max (tp_g09$ Gen), uniqueN (tp_g09$ Year))
指标 数值
<char> <int>
1: 总个体数 27635
2: 最大世代 11
3: 年份数 11
从结构上看,这是一套年份连续、世代信息完整,且末端参考群较大的群体档案,适合同时用于:
单时点参考群体的静态多样性诊断;
多年份动态衰减分析;
漂变、瓶颈与始祖利用失衡三类风险分离。
3.2 Shannon 有效数的实证判读
我们将最后一年(2025 年)的所有个体作为参考群体 进行全面诊断。
# 获取 2025 年出生的参考群 <- tp_g09[Year == 2025 , Ind]# 运行 pediv,visPedigree 将自动给出所有综合指标 <- pediv (tp_g09, reference = ref_2025, top = 20 , seed = analysis_seed)$ summary[, .(fe = round (fe, 3 ),feH = round (feH, 3 ),` feH/fe ` = round (feH / fe, 3 ),fa = round (fa, 3 ),faH = round (faH, 3 ),` faH/fa ` = round (faH / fa, 3 ),fg = round (fg, 3 ),fafe = round (fafe, 3 )
NRef NFounder fe feH feH/fe NAncestor fa faH faH/fa fg
<int> <int> <num> <num> <num> <int> <num> <num> <num> <num>
1: 26222 137 76.866 94.485 1.229 120 62.642 79.196 1.264 18.639
fafe
<num>
1: 0.815
这组结果至少传递出三个信号:
\(f_e^{(H)} / f_e \approx 1.23\) \(f_a^{(H)} / f_a \approx 1.26\) \(f_a / f_e \approx 0.815\)
如果把这些指标合并起来判读,可以得到一个更具体的结论:G09 群体的潜在遗传来源并未完全消失,但这些来源向当代参考群体的传递已经出现明显压缩。换言之,这一结果更接近“遗传库仍有储备,但代际传递效率下降”,而不是“遗传库本身已经耗尽”。对育种决策而言,这一区分十分重要,因为它决定了优先动作应是优化留种结构,还是考虑重建基础群体。
3.3 哪些始祖和祖先最值得重点关注?
只看综合指标还不够,育种管理最终要落实到“哪些个体或家系被用得太多”。下面分别查看 2025 年参考群体中的高贡献始祖和高边际贡献祖先。
Ind Contrib CumContrib Rank
<char> <num> <num> <int>
1: MRYGY15B000M033 0.02702347 0.02702347 1
2: MRYGY15B000F071 0.02326004 0.05028351 2
3: MRYGY15B000M036 0.02326004 0.07354355 3
4: MRTZD15B000F005 0.02301622 0.09655977 4
5: MRTZD15B000M005 0.02301622 0.11957599 5
6: MRYGY21G050M013 0.02292445 0.14250044 6
7: MRYGY15B000F003 0.02270849 0.16520892 7
8: MRYGY15B000M042 0.02270849 0.18791741 8
9: MRYGY15B000F005 0.02131064 0.20922805 9
10: MRYGY15B000M017 0.02131064 0.23053869 10
Ind Contrib CumContrib Rank
<char> <num> <num> <int>
1: MRYGY23G070B641 0.03646747 0.03646747 1
2: MRYGY23G070A255 0.03386469 0.07033216 2
3: MRYGY23G070A629 0.03175768 0.10208985 3
4: MRYGY18G020D491 0.02730085 0.12939070 4
5: MRYGY21G050A142 0.02536992 0.15476061 5
6: MRYGY15B000M033 0.02416353 0.17892415 6
7: MRYGY17G010A801 0.02367347 0.20259761 7
8: MRYGY17G010A333 0.02354893 0.22614654 8
9: MRYGY18G020D679 0.02293071 0.24907725 9
10: MRYGY21G050M013 0.02292445 0.27200171 10
这里要特别注意两个层面的区别:
founders 表中的 Contrib 反映的是起始血统份额 ;ancestors 表中的 Contrib 反映的是剥离重叠后仍然独立解释群体变异的边际贡献 。
如果某些个体在 ancestors 中排名非常靠前,却未必在 founders 中同样突出,通常意味着它们是后续代际中形成的“瓶颈节点”,也就是在繁育历史里被持续高频使用的父母本或家系。
3.4 计算多样性动态与半衰期
接下来利用 pedhalflife(),借助 Year 这条真实时间轴来建模分析遗传多样性的动态变化。
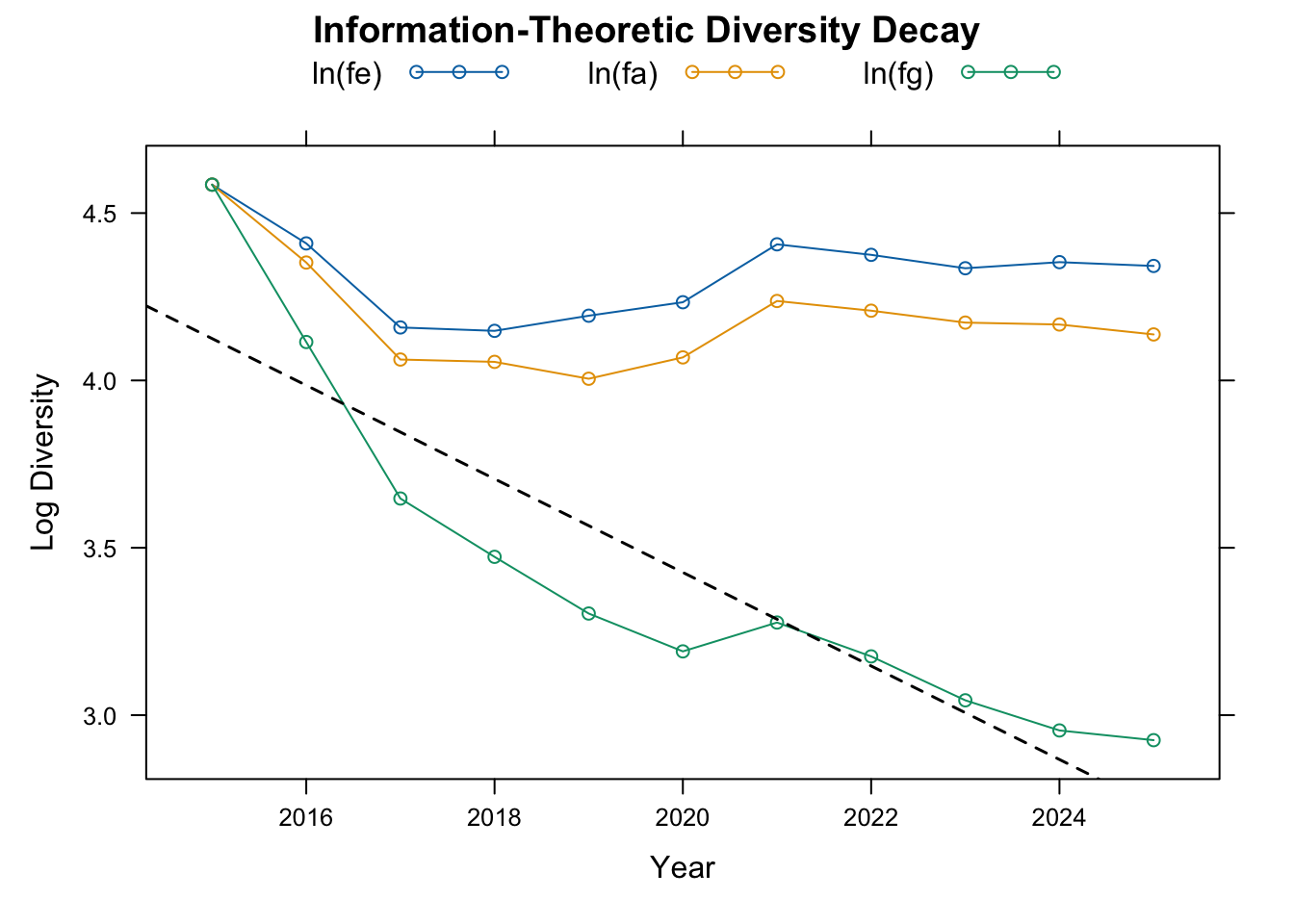
# 使用 Year 追踪多样性随时间的流失率 <- pedhalflife (tp_g09, timevar = "Year" , seed = analysis_seed)print (hl_res)
Information-Theoretic Diversity Half-Life
-----------------------------------------
Total Loss Rate (lambda_total): 0.139734
Foundation (lambda_e) : 0.002187
Bottleneck (lambda_b) : 0.016988
Drift (lambda_d) : 0.120560
-----------------------------------------
Diversity Half-life (T_1/2) : 4.96 (Year)
Timeseries: 11 time points
从打印结果可以看到,该群体的多样性半衰期约为 4.96 年 。这意味着,在“当前结构继续延续”的假设下,始祖基因当量大约每 5 年减半一次。对于闭锁群体而言,这已经是一个值得高度关注的预警信号。
为了更直观地看到多样性变化轨迹,还可以把各年份的等效数列出来:
$ timeseries[, .(fe = round (fe, 2 ),fa = round (fa, 2 ),fg = round (fg, 2 ),lnfafe = round (lnfafe, 3 ),lnfgfa = round (lnfgfa, 3 )
Time NRef fe fa fg lnfafe lnfgfa
<int> <int> <num> <num> <num> <num> <num>
1: 2015 98 98.00 98.00 98.00 0.000 0.000
2: 2016 109 82.22 77.65 61.24 -0.057 -0.237
3: 2017 111 63.96 58.12 38.37 -0.096 -0.415
4: 2018 131 63.32 57.71 32.23 -0.093 -0.583
5: 2019 138 66.25 54.88 27.21 -0.188 -0.701
6: 2020 126 68.97 58.49 24.30 -0.165 -0.878
7: 2021 123 82.00 69.22 26.49 -0.169 -0.961
8: 2022 141 79.46 67.25 23.94 -0.167 -1.033
9: 2023 130 76.34 64.90 21.00 -0.162 -1.128
10: 2024 306 77.74 64.53 19.19 -0.186 -1.213
11: 2025 26222 76.87 62.64 18.64 -0.205 -1.212
plot (hl_res, type = "log" )
从时间序列中可以看到,2015 年作为基础群体起点时,fe = fa = fg,这是符合逻辑的:起始阶段尚未经历后续瓶颈与漂变。之后 fg 持续下降,并逐渐与 fa、fe 拉开距离,说明随机漂变效应在时间上持续累积。
3.5 剖析衰减过程与靶向施策
那么,干预重点应当放在哪里?关键就在 hl_res$decay 给出的衰减分解。
$ decay[, .(LambdaE = round (LambdaE, 6 ),LambdaB = round (LambdaB, 6 ),LambdaD = round (LambdaD, 6 ),LambdaTotal = round (LambdaTotal, 6 ),THalf = round (THalf, 3 )
LambdaE LambdaB LambdaD LambdaTotal THalf
<num> <num> <num> <num> <num>
1: 0.002187 0.016988 0.12056 0.139734 4.96
输出的 \(\lambda_e\) 、\(\lambda_b\) 与 \(\lambda_d\) 分工明确。在这套 G09 数据中,分解结果呈现出较清晰的层次:
\(\lambda_e\) 很小(~0.002):说明始祖利用不均并不是当前的主要矛盾。\(\lambda_b\) 有一定规模(~0.017):说明后续繁育过程中确实形成了可观的瓶颈。\(\lambda_d\) 最大(~0.121)
据此更稳妥的表述是:当前阶段的首要压力来自有限群体中的持续漂变,瓶颈次之,而建群起点的失衡影响相对较小。
对生产的启示: 如果分解格局与本例相似,优先策略通常不是继续压缩核心留种群,而是扩大实际参与下一代的家系面和个体面。让更多平行家系都能留下后代,往往比进一步强化少数“明星家系”的选择强度,更能延缓 \(\lambda_d\) 主导下的多样性流失。
解读边界 :
feH 与 faH 反映的是系谱贡献分布的均匀度,不直接等同于全基因组实测杂合度。T_{1/2} 对时间窗、参考群体定义和留种方式敏感,因此更适合做纵向监测与方案比较。
3.6 从指标组合到育种决策
在实际管理中,单个指标往往不足以支撑决策。更有效的做法,是把 pediv() 给出的静态结构指标与 pedhalflife() 给出的动态衰减指标联合起来解释。下面给出一个更接近年度决策场景的判读框架:
feH/fe 接近 1,且 \(\lambda_e\) 较高始祖层面的遗传来源已经偏窄,且这种不均仍在持续强化
重新审视基础群构成;必要时考虑引入新始祖、外部材料或扩展保种基础群
fa/fe 较低,且 \(\lambda_b\) 较高历代繁育中存在明显瓶颈,核心父母本被重复使用
对高边际贡献祖先设置使用上限;分散配种机会;降低单一明星家系的后代占比
feH/fe 与 faH/fa 均较高,但 \(\lambda_d\) 主导长尾仍然存在,但未被稳定续留,漂变正在持续吞噬低频家系
扩大每代保留家系数;提高低频家系的续留概率;控制父母本贡献偏斜
feH/fe 较高而 \(T_{1/2}\) 持续缩短潜在多样性仍在,但流失速度加快
将“抢救性保留边缘家系”作为短期重点,并在下一繁殖周期复测干预效果
这个框架的核心思想是:feH/faH 反映的是潜在遗传来源是否仍在 ,fa/fe 反映的是传递过程是否已经收缩 ,而 \(\lambda_e\) 、\(\lambda_b\) 、\(\lambda_d\) 进一步说明收缩主要发生在哪个阶段 。只有把这三层信息叠加起来,育种决策才不至于停留在“多保留一些家系”这样过于宽泛的建议上。
从 G09 的结果看,更合理的动作顺序应是:
先控制漂变。 通过提高每代实际留种规模、增加平行家系数、降低父母本贡献偏斜,直接针对 \(\lambda_d\) 主导的问题。同步约束瓶颈节点。 对 ancestors 表中长期居前的个体或家系实施使用阈值,避免 \(\lambda_b\) 进一步抬升。定向续留长尾来源。 当 feH/fe 与 faH/fa 显著高于 1 时,说明边缘家系仍具有管理价值,应通过保留配额、分层留种或平衡交配设计确保其进入下一代。用下一年度结果验证干预是否有效。 如果干预后 \(T_{1/2}\) 延长、\(\lambda_d\) 下降、fa/fe 回升,则说明策略方向基本正确;反之,则应重新评估配种强度与留种面。
一个实用的快速判读框架 :
feH/fe 高:说明始祖层面仍有长尾;faH/fa 高:说明祖先层面仍有长尾;fa/fe 低:说明瓶颈明显;lambda_d 高:说明第一优先级不是继续压缩核心群,而是先把群体留大、留宽。
四、pediv() 与 pedhalflife() 联合用于年度育种监控的标准流程
如果目标不是一次性的事后分析,而是建立一个可重复执行的年度监控体系,那么 pediv() 与 pedhalflife() 最好被放在同一套固定流程中。一个相对稳健的年度工作流通常包括以下五步:
4.1 第一步:固定数据口径与参考群体定义
年度监控最忌讳的是“每年换一套统计口径”。在进入分析前,至少应固定以下三项:
系谱冻结时点 :每年在同一业务节点冻结一次完整系谱。参考群体定义 :例如固定为“当年全部候选留种个体”或“当年进入核心群的个体”。时间窗口定义 :pedhalflife() 应明确使用累计历史窗口还是固定长度滚动窗口,并长期保持一致。
如果这三项定义在年度之间频繁变化,那么指标的年际可比性会明显下降。
4.2 第二步:用 pediv() 完成当前年度的结构诊断
pediv() 适合回答“今年的参考群体结构如何”这一问题。年度报告中建议至少固定输出以下内容:
fe、feH、fa、faH、fg;feH/fe、faH/fa、fa/fe 三个比值;founders 与 ancestors 表的前若干名个体。
其中,前一组指标用于判断多样性总量与长尾保留情况,后一组列表用于定位具体的高贡献始祖、瓶颈祖先或需要特别关注的家系。
4.3 第三步:用 pedhalflife() 评估年际趋势与风险来源
pedhalflife() 适合回答“过去若干年中,多样性正在怎样变化”这一问题。年度监控中至少应跟踪:
THalf:衡量总体流失速度;LambdaE:反映始祖利用不均的动态变化;LambdaB:反映瓶颈是否在加强;LambdaD:反映漂变是否成为主导风险。
在解释这些结果时,建议把重点放在年际变化方向 而不是单年绝对值。对管理者而言,THalf 从 8 年缩短到 5 年,通常比“当前数值究竟是 5.0 还是 5.3”更值得重视。
4.4 第四步:把指标映射为管理触发条件
年度监控真正有用的前提,是指标变化能够触发明确动作。下面给出一组示例性规则,这些阈值并非普适标准,但可以作为制定内部 SOP 的起点:
当 fa/fe 连续下降时,启动对热门父母本使用结构的复核。
当 LambdaB 升高时,收紧高边际贡献祖先的使用上限。
当 LambdaD 长期占主导时,优先扩大留种规模和家系覆盖面,而不是进一步提高选择强度。
当 feH/fe 或 faH/fa 仍高而 THalf 快速缩短时,说明潜在长尾尚在,但其传递正在加速丢失,应启动边缘家系的定向续留。
当 feH/fe 接近 1 且 LambdaE 同时升高时,应讨论是否需要扩展基础群体或引入新血统。
换言之,监控体系不能只停留在“出报表”,而应进一步进入“触发动作”的层面。
4.5 第五步:形成年度闭环并追踪干预结果
一个完整的年度闭环,至少应包含以下输出:
当年的结构诊断结果;
当年的动态风险分解;
据此调整的配种、留种或保种措施;
下一年度对这些措施效果的复测。
只有当监控结果被用于调整实际配种方案,并在下一年度被再次验证时,pediv() 与 pedhalflife() 才真正从分析工具转化为管理工具。
4.6 一个可复用的年度监控代码模板
下面给出一个简化的代码模板,用于生成某一年度的监控面板。实际生产中,可以把它封装为固定脚本,每年在同一数据冻结节点执行。
<- 2025 L# 参考群体定义:当年个体 <- tp_g09[Year == monitor_year, Ind]# 若需要构建截至 monitor_year 的完整分析对象,可先截取子系谱 <- tidyped (cand = tp_g09[Year <= monitor_year, Ind],trace = "up" # 当前年度的静态结构诊断 <- pediv (reference = ref_ids,top = 20 ,seed = analysis_seed# 历史趋势与衰减来源诊断 <- pedhalflife (timevar = "Year" ,seed = analysis_seed# 生成年度监控面板 <- iv_res$ summary[, .(Year = monitor_year,feH_fe = feH / fe,faH_fa = faH / fa,fa_fe = fa / fe` := ` (THalf = hl_res$ decay$ THalf,LambdaE = hl_res$ decay$ LambdaE,LambdaB = hl_res$ decay$ LambdaB,LambdaD = hl_res$ decay$ LambdaD
实施建议 :
若用于年度监管,务必固定参考群体定义与时间窗口定义。
若用于不同群体横向比较,应优先比较变化方向与相对结构,而不是机械比较绝对值。
若群体规模较大,建议把年度面板、Top 祖先列表和触发动作记录保存为同一份管理档案。
五、总结
经典 \(f_e\) 、\(f_a\) 告诉我们多样性还剩多少,\(f_e^{(H)}\) 、\(f_a^{(H)}\) 进一步告诉我们长尾是否仍在,而 pedhalflife() 则把“剩多少”转化为“流失得多快”。三者结合,才能把系谱多样性的静态结构与动态趋势放到同一张图上理解。
对 G09 群体而言,更需要警惕的不是始祖数量本身,而是每代真正进入下一轮繁育的遗传样本面过窄。换句话说,问题的重点不是“是否存在长尾来源”,而是“这些长尾来源能否被稳定地传递下去”。如果后续管理能在维持选择响应的同时,扩大基础群、均衡父母本贡献并持续续留边缘家系,那么半衰期就有机会被显著拉长。
因此,从方法学上看,pediv() 更适合承担“年度结构体检”的角色,pedhalflife() 更适合承担“历史趋势预警”的角色。把两者纳入统一的年度 SOP,才能使多样性管理从静态描述走向可执行、可追踪、可复核的育种决策流程。
六、参考文献
Boichard, D., Maignel, L., & Verrier, É. (1997). The value of using probabilities of gene origin to measure genetic variability in a population. Genetics Selection Evolution , 29(1), 5-23.
Caballero, A., & Toro, M. A. (2000). Interrelations between effective population size and other pedigree tools for the management of conserved populations. Genetical Research , 75(3), 331-343.
Hill, M. O. (1973). Diversity and evenness: a unifying notation and its consequences. Ecology , 54(2), 427-432.
Jost, L. (2006). Entropy and diversity. Oikos , 113(2), 363-375.
Lacy, R. C. (1989). Analysis of founder representation in pedigrees: founder equivalents and founder genome equivalents. Zoo Biology , 8(2), 111-123.